ControlNet - 짐승을 길들이는 방법 1
안녕하세요, Cocone M에서 AI 개발자로 재직중인 Gnosis 임준규라고 합니다.
최근에 나온 Stable diffusion에 대한 adapter 모델이라고 할 수 있는 ControlNet과 T2I Adapter에 대해 전달 드리고자 합니다. 이 글에서는 먼저 ControlNet에 대해 알아보겠습니다.
개요
최근 GPT3.5, GPT4 와 같은 대형 모델이 강력한 성능을 자랑하고 있습니다. 이러한 환경에서 그만큼의 리소스에 접근할 수 없는 기업이나 개인이 딥러닝 모델 자체를 다룬다는 일은 부질없어 보이기까지 합니다.
이에 대처하는 방안은 단순하게 바라보자면 다음과 같을 것입니다.
- 대항할만한 모델을 만든다
- 대형화된 모델을 활용할 수 있는 방안을 만든다
이번에 소개드릴 내용은 두번째 방안에 해당하는 내용입니다. 대형화된 모델을 단순 사용이 아닌, 기술적으로 제어하는 방법을 구현한다면 충분한 의미를 가질 수 있다고 생각합니다. 거대 서사에 맞선 해체와 개인화는 선택이 아닌 필연일 것입니다.
ControlNet
모델 개요
ControlNet의 사상을 요약하자면, “원본 모델의 성능을 유지하면서, 새로운 task -새로운 형태의 input-을 제어하는 모델을 만들고 싶다.” 라고 볼 수 있습니다.
다들 아시다시피 Stable diffusion은 뛰어난 퀄리티를 가진 다양한 이미지를 생성할 수 있습니다. 다만 문제가 있다면, 기존 모델 그 자체로는 사용자가 원하는 결과를 얻기 위해서 prompt라는 한정된 방법으로만 제어가 가능하다는 것입니다. 그렇다고 사용자가 원하는 형태로 task-specific하게 stable diffusion을 학습하기 위해서는 막대한 양의 데이터와 리소스가 필요합니다.
나도 이런 게 하고 싶다 - NVIDIA Canvas
이러한 문제를 ControlNet은 복잡하지 않은 아이디어로 해결하면서도, 뛰어난 성능과 다양한 활용성을 가진 Stable diffusion 응용 방법을 제시합니다. 이와 같은 adapter 모델이 새롭거나 특이한 모델인 것은 아닙니다. 이미 각 Vision, NLP 분야에서 획을 그은 논문들도 존재합니다. 하지만 개인적으로는 오히려 기존에 있던 방법론을 몇 가지 아이디어로 강력하게 만들었다는 것이 더욱 매력적으로 다가 왔습니다.
ControlNet이 Stable Diffusion을 제어하는 방법
크게 두 가지의 방법을 통해 Stable diffusion에 부가적인 neural network을 추가하게 됩니다.
-
zero-convolution
-
Weight, Bias 모두 0으로부터 시작하는 layer를 의미합니다. zero-convolution layer 의 gradient는 다음과 같이 계산됩니다.
- weight를 W, bias를 B, Input이 I일 때, 순방향 전파는 다음과 같은 식으로 표현됩니다.
$Z(I; {W, B}){p,i} = B_i + \sum\limits_j^c I{p,i}W_{i,j} $
-
이때 zero-convolution의 gradient를 구하면 다음과 같습니다.
$\frac{∂Z(I; {W, B}){p,i}}{∂Bi} = 1$
$\frac{∂Z(I; {W, B}){p,i}}{∂I_{p,i}} = \sum\limits_j^c W_{i,j} = 0$
$\frac{∂Z(I; {W, B}){p,i}}{∂W{i,j}} = I_{p,i} \neq 0 $ - 위에서 볼 수 있듯이, Input이 0이 아니라면, Weight의 gradient는 0이 아닙니다.
- 참조: https://github.com/lllyasviel/ControlNet/blob/main/docs/faq.md
- weight를 W, bias를 B, Input이 I일 때, 순방향 전파는 다음과 같은 식으로 표현됩니다.
-
zero-convolution layer는 0으로부터 점진적으로 학습됩니다. 이는 후술할 학습 과정에 용이한 특성으로 작용합니다.
-
-
Trainable copy
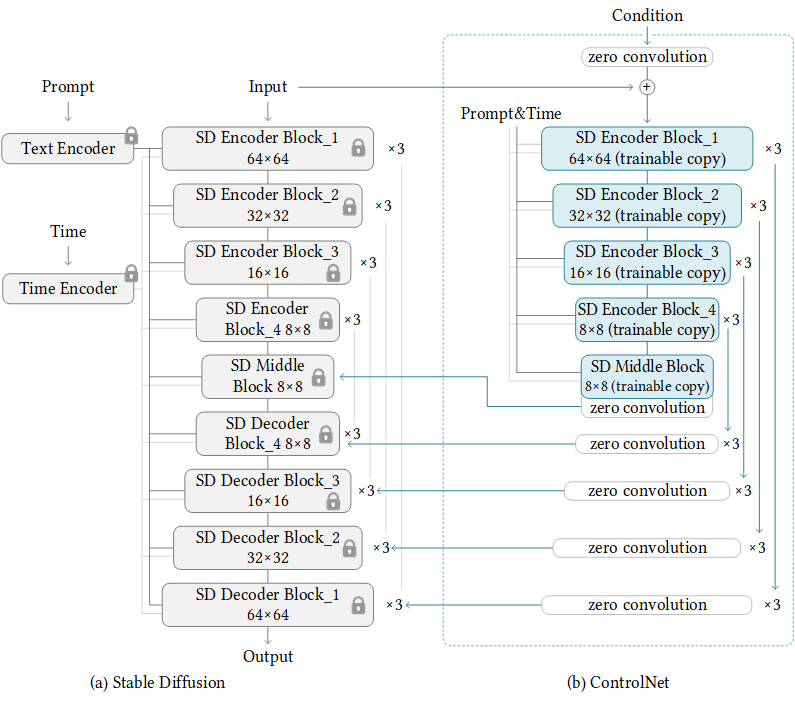
- 좌측은 원본 그대로의 Stable Diffusion 모델입니다. 학습되지 않은 그대로 추론에 사용됩니다.
- 우측이 ControlNet의 본체라고 할 수 있습니다. 학습이 가능한 부분이며, Encoder block과 decoder를 대체한 zero convolution layer로 이루어집니다.
- Encoder block을 사용하는 이유는 새로운 형태의 데이터에 대한 정보를 학습하기에 더 용이하기 때문입니다. 다만 여기서 어쩔 수 없이 encoder의 semantic structure가 손상되는데, 점진적으로 학습되는 zero-convolution layer를 사용하여 이 영향을 최소화합니다.
이 과정을 통해 데이터가 적은 상황에서도, 원본 모델의 semantic structure를 유지한 채 새로운 task를 학습할 수 있습니다. 결과적으로 Stable diffusion 모델에 간단하게 부착 가능한 형태로, 더 적은 메모리와 빠른 속도로 학습이 가능합니다.
한계점이라고 한다면, Stable diffusion의 강력한 성능을 보존하는 만큼 뼈대가 되는 모델의 성능에 종속적인 결과가 나타날 수 밖에 없어 보인다는 것입니다.
활용

위와 같은 윤곽선 이미지를 통해 적절한 이미지를 생성해내는 Image to Image 생성 과정을 상대적으로 적은 데이터로 학습 가능합니다.

다양한 Condition image를 활용도에 맞게 shape만 조절해주면 학습이 가능합니다. 위는 포즈를 재현하는 모델의 output 입니다. 마이클 잭슨의 콘서트라는 prompt를 사용한 Text to Image 과정에 포즈 condition image를 더한 사용이 가능합니다.
결론
오늘은 ControlNet에 대해 알아보았습니다. 제 짧은 지식으로는 다른 분야에 적용될 수 있을지 예상하기는 힘듭니다만, 앞으로 이러한 대형 모델을 제어하는 기술의 중요성은 점점 커지지 않을까 생각합니다.
다음 시간에는 비슷하지만 또 다른 T2I Adapter에 대해 알아보고, ControlNet과 동시에 활용하는 방법을 알아보도록 하겠습니다.
Reference
**Adding Conditional Control to Text-to-Image Diffusion Models :** https://arxiv.org/abs/2302.05543
Nvidia cavnas : https://www.nvidia.com/en-eu/studio/canvas/
**Learning multiple visual domains with residual adapters :** https://arxiv.org/abs/1705.08045
**Parameter-Efficient Transfer Learning for NLP :** https://arxiv.org/abs/1902.00751