Vector DB
Vector DB ?
데이터베이스의 발전은 기술, 비즈니스, 사회적 요인이 조합되어 형성되고 있습니다. 기술적인 요인에서는 하드웨어의 성능 향상, 분산 컴퓨팅, 클라우드 기술 등이 데이터베이스 시스템의 성능과 확장성을 향상시키고 새로운 형태의 데이터베이스를 가능하게 합니다. 비즈니스 요인에서는 기업의 데이터 중심적인 관리 필요성이 증가함에 따라 데이터베이스는 기업의 핵심 자산으로 인식되고 있습니다. 실시간 데이터 분석, 의사 결정 지원, 고객 경험 개선 등을 위해 데이터베이스 시스템은 점차적으로 더 복잡하고 특화된 기능을 제공하고 있습니다. 사회적 요인에서는 데이터의 규제와 보안, 개인정보 보호에 대한 요구가 강화되면서 데이터베이스 시스템은 더욱 신뢰성과 안전성을 강조하는 방향으로 발전하고 있습니다. 또한, 사회적으로 다양한 분야에서의 데이터 활용이 급증하면서 다양한 종류의 데이터베이스가 필요로 되고 있습니다.
이러한 다양한 데이터베이스 시스템의 발전은 다양한 데이터 관리 요구에 대응하고, 특히 특정 유형의 데이터나 작업에 특화된 솔루션을 제공함으로써 다양한 응용 분야에서 활용될 수 있게 되었습니다.
RDBMS (Relational Database Management System)는 고도로 구조화된 데이터를 효과적으로 저장하고 관리하는 데에 강점을 가지고 있습니다. 트랜잭션 처리와 ACID 속성을 제공하여 데이터 일관성과 안전성을 보장합니다. 반면에 NoSQL은 비구조화된 데이터나 대규모 분산 시스템에서의 유연한 확장성과 높은 성능을 제공하여 다양한 형태의 데이터를 다룰 수 있습니다. GraphDB는 그래프 데이터 모델을 기반으로 하여 복잡한 관계를 효과적으로 표현하고 탐색할 수 있는 특성을 가지고 있습니다. 이는 소셜 네트워크 분석, 지리 정보 시스템, 추천 시스템 등에서 유용하게 활용되고 있습니다.
최근에는 AI 기술의 발전과 보편화로 함께 벡터 데이터베이스가 주목을 받고 있습니다. 벡터 데이터베이스는 벡터 형태로 데이터를 저장하고 처리함으로써 유사성 검색, 패턴 인식, 자연어 처리 등 다양한 AI 응용에 적합한 특성을 제공합니다. 이는 특히 대규모 및 고차원의 벡터 데이터를 다루는 데에 효과적이며, AI 모델의 임베딩 및 유사성 분석과 같은 작업에 중요한 역할을 할 수 있습니다.
</br>
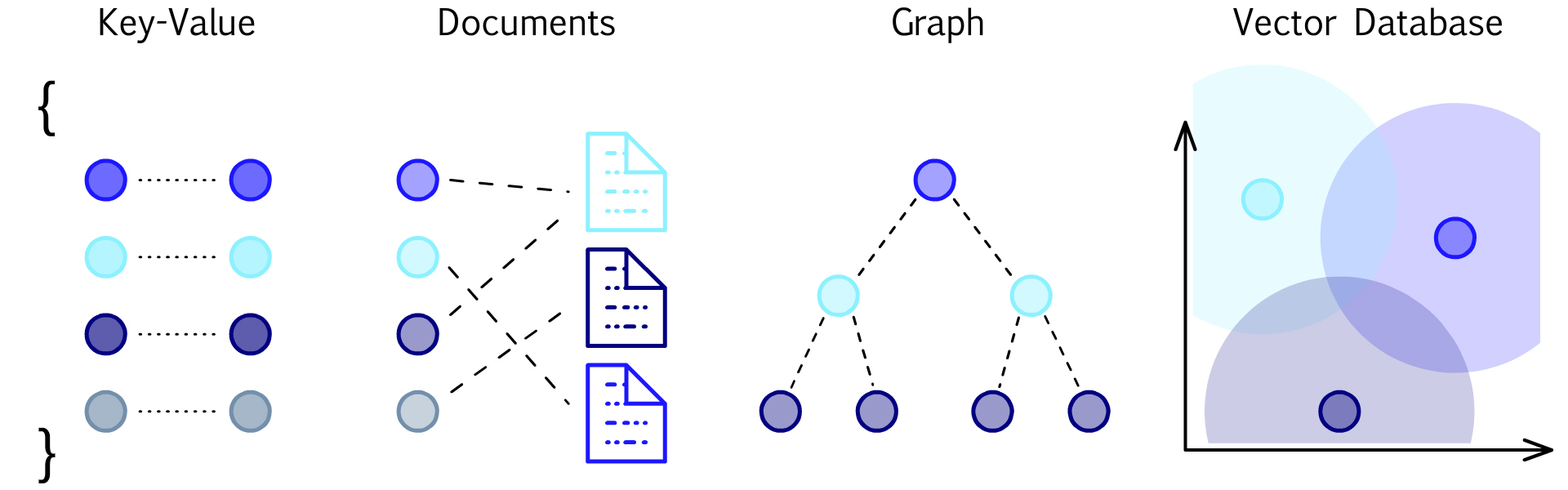 <p align="center">출처 : pinecone</p>
<p align="center">출처 : pinecone</p>
Vector DB의 발전은 비정형 데이터의 효과적인 관리와 활용에 큰 기여를 하고 있습니다. 비정형 데이터는 과거에는 다루기 어려웠지만, AI 기술의 발전으로 인해 이를 정형화된 다차원 벡터로 변환하고 저장할 수 있게 되었습니다. 이로써 데이터베이스 시스템은 더욱 유연하고 다양한 형태의 정보를 효과적으로 처리할 수 있게 되었습니다.
Vector DB는 주로 벡터 공간 모델을 기반으로 하여 데이터를 표현하고 저장합니다. 이는 데이터 간의 유사성을 벡터 간의 거리나 유사도로 측정할 수 있게 해주어, 유사성 검색 및 추천 시스템에서 강력한 성능을 발휘합니다. 또한, 벡터를 통한 데이터 표현은 다양한 기계 학습 및 딥 러닝 모델과의 통합을 용이하게 만들어, 데이터 과학 및 인공 지능 분야에서의 응용 가능성을 크게 확장시켰습니다.
이러한 Vector DB의 특성은 특히 이미지, 텍스트, 오디오 등의 다양한 형태의 비정형 데이터에 대한 효과적인 저장 및 분석을 가능케 합니다. 예를 들어, 이미지 데이터의 경우 각 픽셀을 벡터로 표현하여 유사한 이미지를 검색하거나, 자연어 처리 분야에서는 단어나 문장을 벡터로 변환하여 의미적 유사성을 측정하는 데에 활용됩니다.
총론적으로, Vector DB의 발전은 AI 기술과의 시너지를 통해 비정형 데이터를 효과적으로 다룰 수 있는 새로운 가능성을 열고 있으며, 다양한 응용 분야에서 혁신적인 솔루션을 제공하고 있습니다. </br>
*
Vector DB의 특징
-
다차원 벡터 지원 : 주로 수치형 데이터를 다차원 벡터로 표현하고 저장할 수 있습니다. 이는 복잡한 데이터 패턴 및 관계를 표현하는 데 유용합니다.
-
벡터 검색 및 유사성 측정 : Vector DB의 주된 목적은 벡터 간의 유사성을 검색하고 근접 이웃을 찾는 것입니다. 이를 통해 유사한 데이터를 효과적으로 식별하고 검색할 수 있습니다.
-
고성능 및 최적화 : 대용량의 벡터 데이터를 빠르게 처리하기 위한 성능 및 최적화가 중요한 특징입니다. 특히 실시간 처리에 대한 높은 성능을 제공합니다.
-
비정형 데이터 처리 : 주로 텍스트, 이미지, 음성과 같은 비정형 데이터를 효과적으로 다룰 수 있습니다. 이는 다양한 유형의 데이터를 통합하여 저장하고 분석하는 데에 유용합니다.
-
기계 학습 및 데이터 분석 지원 : 벡터 데이터베이스는 기계 학습 모델에 입력 데이터를 제공하고 결과를 분석하는 데 사용됩니다. 이는 AI 및 데이터 분석 작업에 적합한 특징을 제공합니다.
-
실시간 처리 및 분석 : Vector DB는 대규모의 벡터 데이터를 실시간으로 처리하고 분석할 수 있는 능력을 갖추고 있어, 실시간 응용 및 의사 결정에 활용됩니다.
-
스케일 아웃 가능성 : 대용량 및 다양한 유형의 벡터 데이터에 대한 스케일 아웃(확장성)을 지원하여 성능을 유지하면서 데이터 양이 증가해도 대응할 수 있습니다.
-
유연성과 확장성 : 다양한 벡터 유형과 데이터 구조에 대한 유연성을 제공하며, 새로운 기능이나 데이터 유형이 추가되더라도 쉽게 확장할 수 있는 구조를 가지고 있습니다.
Vector DB 사용하기
현재 Vector DB가 활발한 개발이 이뤄지고 있으며, 다양한 라이브러리가 존재하고 있습니다. 이 중에서 PostgreSQL을 기반으로 한 PG Vector를 활용하여 유사성 측정을 테스트해보려고 합니다.
1. PostgreSQL 설치
현재 사용하고 있는 운영 체제는 Ubuntu 18.04로 apt를 통해 설치할 시 postgreSQL-9 버전이 설치가 됩니다.
하지만, PG Vector를 사용하기 위해선 최소 11버전 이상의 postgreSQL을 설치해야 됨으로 아래와 같이 진행하게 되었습니다.
#GPG 키 다운로드
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
#repo 추가
echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list
#목록 업데이트 및 postgreSQL 설치
apt update && apt install -y postgresql-15 postgresql-server-dev-15
공식 홈페이지에 나와 있는 방법을 통해 설치하려 했지만, 패키지 목록이 업데이트가 되지 않는 문제가 있었습니다. 그 이유는 postgreSQL이 18.04 버전의 경우 repo를 아카이브로 옮기게 되면서 주소가 바뀌게 되어 해당 부분을 수정해주고 다시 설치를 진행하게 되었습니다.
#GPG 키 다운로드
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
#repo 추가
echo "deb http://apt-archive.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list
#목록 업데이트 및 postgreSQL 설치
apt update && apt install -y postgresql-15 postgresql-server-dev-15
아래의 코드를 이용해 PostgreSQL의 버전을 확인
pg_config --version
#PostgreSQL 15.3 (Ubuntu 15.3-1.pgdg18.04+1)
psql을 통해 기본적인 셋팅 진행
# postgres 유저로 전환
sudo -i -u postgres
# postgreSQL 접속
psql
# admin이라는 슈퍼 유저 생성
postgres=# CREATE USER admin PASSWORD '1234' SUPERUSER;
# testdb 데이터 베이스 생성
postgres=# CREATE DATABASE testdb;
2. PG Vector 설치
PG Vector는 PostgreSQL의 Extension으로 PG Vector의 공식 GitHub repository를 통해 설치가 가능합니다.
git clone --branch v0.5.1 https://github.com/pgvector/pgvector.git
cd pgvector
make
3. Python 에서 PostgreSQL 접속하기
Python 에서 PostgreSQL 접속을 위해선 psycopg2를 이용하여 접속을 할 수 있습니다.
pip install psycopg2-binary
설치가 완료 되면 로컬에 설치된 PostgreSQL에 접속을 확인
import psycopg2
db_params = {
'host': "127.0.0.1",
'database': 'testdb',
'user': 'admin',
'password': '1234',
'port': '5432',
}
conn = psycopg2.connect(**db_params)
cursor = conn.cursor()
cursor.execute("SELECT 1;")
print(cursor.fetchone())
#(1,)
4. CLIP을 활용한 Sentence Embedding
PG Vector를 사용하기 위한 셋팅은 마무리가 되었습니다. 이제 본격적으로 Vector DB 를 활용할 수 있도록 Vector를 만들면 되는데, 다른 Vector DB들의 경우 DB에 String을 추가하게 되면 DB 내에 있는 Text Encoder 모델을 통해 자동으로 Vector 로 전환하게 됩니다. 하지만 PG Vector의 경우 Text Encoder 모델을 통해 Vector화를 진행해야 합니다.
그래서 저는 Open AI가 배포한 CLIP 모델을 통해 Vector화를 진행하려 했고, 추가적으로 오픈 데이터 셋을 가져오기 위한 라이브러리 설치가 필요합니다.
pip install transformers datasets
이번 테스트에 사용된 오픈 데이터 셋은 embedding-data/sentence-compression라는 데이터 셋을 사용할 예정입니다. 해당 데이터셋은 유사한 문장끼리 짝 지어진 데이터 셋으로 첫 번째 문장은 원본 텍스트를 그대로, 두 번째 문장의 경우 Sentence embedding으로 변환 한 후 사용할 예정입니다.
from datasets import load_dataset #huggingface에 배포된 데이터 셋을 불러오기 위한 라이브러리
from transformers import CLIPProcessor, CLIPModel #CLIP모델
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
dataset = load_dataset("embedding-data/sentence-compression")
dic = {}
for data in dataset['train']['set'] :
key, text = data
inputs = processor(text=text, return_tensors="pt", max_length=77)
features = model.get_text_features(inputs['input_ids'])[0].detach().tolist()
dic[key] = features
※ Sentence Embedding 이란? 텍스트나 문장을 고정 차원의 벡터로 나타내는 과정
5. PG Vector CRUD 테스트
PostgreSQL 설치와 데이터베이스에 넣은 데이터도 모두 준비가 완료 되었습니다. 준비된 데이터를 이용하여 CRUD 테스트를 진행하도록 하겠습니다.
처음으로 테이블을 생성해줘야 하는데, 저희는 PG Vector를 활용하기 위해선 vector라는 형식으로 정의 해주면 기존 테이블 생성과 같습니다.
import psycopg2
db_params = {
'host': "127.0.0.1",
'database': 'testdb',
'user': 'admin',
'password': '1234',
'port': '5432',
}
conn = psycopg2.connect(**db_params) # PostgreSQL 연결
cursor = conn.cursor()
시작 전 PG Vector Extension을 설치해줘야 합니다
cursor.execute("CREATE EXTENSION vector;")
테이블 생성을 위한 코드를 작성해 줍니다.
create_table_query = """
CREATE TABLE IF NOT EXISTS vector_table (
id SERIAL PRIMARY KEY,
text VARCHAR(255),
embedding vector(512)
)
"""
CRUD 작업을 위한 함수를 정의해줍니다.
def create_record(cursor, text, embedding):
query = "INSERT INTO vector_table (text, embedding) VALUES (%s, %s)"
cursor.execute(query, (text, embedding))
def read_records(cursor):
query = "SELECT * FROM vector_table "
cursor.execute(query)
return cursor.fetchall()
def update_record(cursor, id, embedding):
query = "UPDATE vector_table SET embedding = %s WHERE id = %s"
cursor.execute(query, (id, embedding))
def delete_record(cursor, id):
query = "DELETE FROM vector_table WHERE id = %s"
cursor.execute(query, (id,))
하지만 대용량의 데이터를 INSERT 하기에는 해당 함수로는 무리가 있다.
from psycopg2.extras import execute_values
def create_recoder(cursor, data):
query = "INSERT INTO vector_table (text, embedding) VALUES %s"
execute_values(curosr, query, data)
만들어 둔 데이터를 추가하기 위해 형식 변환이 필요하다.
data = [(k, v) for k, v in dic.items()]
이제 모든 준비는 끝났고 데이터를 추가 한다.(전체 코드)
import psycopg2
from psycopg2.extras import execute_values
from datasets import load_dataset
from transformers import CLIPProcessor, CLIPModel
def create_recods(cursor, data):
query = "INSERT INTO vector_table (text, embedding) VALUES %s"
execute_values(curosr, query, data)
def read_records(cursor):
query = "SELECT * FROM vector_table "
cursor.execute(query)
return cursor.fetchall()
def update_record(cursor, id, embedding):
query = "UPDATE vector_table SET embedding = %s WHERE id = %s"
cursor.execute(query, (id, embedding))
def delete_record(cursor, id):
query = "DELETE FROM vector_table WHERE id = %s"
cursor.execute(query, (id,))
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
dataset = load_dataset("embedding-data/sentence-compression")
dic = {}
for data in dataset['train']['set'] :
key, text = data
inputs = processor(text=text, return_tensors="pt", max_length=77)
features = model.get_text_features(inputs['input_ids'])[0].detach().tolist()
dic[key] = features
data = [(k, v) for k, v in dic.items()]
db_params = {
'host': "127.0.0.1",
'database': 'testdb',
'user': 'admin',
'password': '1234',
'port': '5432',
}
create_table_query = """
CREATE TABLE IF NOT EXISTS vector_table (
id SERIAL PRIMARY KEY,
text VARCHAR(255),
embedding vector(512)
)
"""
conn = psycopg2.connect(**db_params)
cursor = conn.cursor()
cursor.execute("CREATE EXTENSION vector;")
cursor.execute(create_table_query)
create_recods(cursor, data)
conn.commit()
conn.close()
모든 데이터가 PostgreSQL 데이터베이스가 추가가 됐는데, PG Vector의 핵심 기술인 L2 distance 기능을 통해 해당 Vector와 유사한 ID를 찾도록 하겠습니다.
query = "SELECT id, text FROM vector_table ORDER BY RANDOM() LIMIT 1;"
cursor.execute(query)
id, text = cursor.fetchone()
inputs = processor(text=text, return_tensors="pt", max_length=77)
features = model.get_text_features(inputs['input_ids'])[0].detach().tolist()
query = f"SELECT id FROM vector_table ORDER BY embedding <-> '{features}' LIMIT 10;"
cursor.execute(query)
랜덤한 텍스트를 가져와 Sentence embedding으로 변환 한 후, 데이터 베이스 내에 embedding 컬럼에서 가장 근접한 데이터를 10개 가져오는 쿼리입니다.
여기서 핵심 쿼리는 <->으로 L2 distance를 계산하는 쿼리입니다. 그 밖에도 inner product (<#>), cosine distance (<=>)을 사용하시면 됩니다.
이제 L2 distance를 계산하는 쿼리를 알았으니, 얼마나 잘 찾는지도 확인을 해 보겠습니다.
def l2_distance_test(cursor, n, processor, model) :
top1 = 0
top5 = 0
top10 = 0
for _ in range(n) :
query = "SELECT id, text FROM vector_table ORDER BY RANDOM() LIMIT 1;"
cursor.execute(query)
id, text = cursor.fetchone()
inputs = processor(text=text, return_tensors="pt", max_length=77)
features = model.get_text_features(inputs['input_ids'])[0].detach().tolist()
query = f"SELECT id FROM vector_table ORDER BY embedding <-> '{features}' LIMIT 10;"
cursor.execute(query)
idx = [v[0] for v in cursor.fetchall()]
try :
loc = idx.index(id)
if loc == 0 :
top1 += 1
if loc < 5 :
top5 += 1
top10 += 1
except :
pass
top1_acc = top1/n
top5_acc = top5/n
top10_acc = top10/n
return n, top1_acc, top5_acc, top10_acc
해당 함수를 통해 N=100 계산된 accuracy 는 top1(0.48), top5(0.61), top10(0.63)으로 확인 되었고 정확도를 높이기 위해선 Text Encoder모델을 추가적으로 학습을 하는 방법과 좀 더 큰 모델을 사용하면 accuracy는 올라갈 수 있을 것 같습니다.
마치며…
이전에 설명한 것처럼, 벡터 데이터베이스를 통한 서비스 운영은 다양한 이점을 제공할 수 있습니다. PostgreSQL의 Extension 중 하나인 PG Vector를 사용한 것은 훌륭한 시작이었지만, 다른 오픈소스 벡터 데이터베이스들도 참고할 가치가 있습니다. 이러한 기술들을 통해 더 효율적으로 데이터를 다루고 서비스의 성능을 향상시킬 수 있을 것입니다.
또한, 벡터 데이터베이스를 도입할 때에는 몇 가지 주요 고려 사항이 있습니다. 서비스의 요구 사항, 성능, 확장성, 그리고 보안 등을 고려하여 신중한 평가가 필요합니다.
마지막으로, 여러 벡터 데이터베이스를 통해 코코네 서비스에 적용할 수 있는 다양한 방법을 고려하고 있으며, 다른 분들도 이러한 최신 기술들을 서비스에 효과적으로 적용해 나가면 서비스 운영에 많은 도움이 될 것 같습니다.